
“Cache in memory uses server memory to store cached data. This type of cache is suitable for a single server or multiple servers using session affinity. Session affinity is also known as “Sticky Sessions”. Session affinity means that client requests are always forwarded to the same server for processing.”
- Microsoft
There are at least two types of cache:
-
Memory Cache: widely used, considered the simplest and very effective, significantly improves application performance;
-
Distributed Cache: shared by multiple servers, can store data on servers that do not share the same memory. It’s typically used in larger scale scenarios and automatic resource provisioning.
Today, I will talk a little about Memory Cache, pointing out its advantages and disadvantages, how to implement it, and the appropriate scenarios for using it.
Memory cache is commonly used in scenarios where there is little mutability of information returned from an application server. Anything that rarely changes can be a great candidate for adding the data in cache. The main idea is to ensure that the requested information, for example, from a web/mobile application, reaches the backend layer and does not need to fetch the same information from a data source every time. Essentially, the cache sits between the application and our data source.
This is a great option for specific parts of our application that may be frequently accessed, but generally don't change often, for example:
-
Product categories
-
Districts
-
Councils
-
Parishes
-
Marital status
-
Units of measurement
The request process occurs the first time by typically retrieving the data from the data source. However, before providing the response, we add the data in memory, referencing it with a unique key and an expiration time. These are the basic characteristics of a cache:
-
Unique key that identifies the data in memory and allows us to retrieve it;
-
Actual data that we want to store in memory;
-
Expiration time, which is the duration the data will remain available in memory.
ADVANTAGES
There are numerous advantages. In my opinion, the main ones are:
- Saving resources consumed by an application in the cloud when there is no need to overload the data source for every request;
- Significantly improving the customer experience due to very fast response times;
- Reliability in the returned data;
- Reducing the trips to the data source.
DISADVANTAGES
- Data may not be up to date until the expiration time has occurred;
- Increased maintenance efforts;
- Potential scalability issues.
The use of memory cache must be very well thought out from a business rules perspective. I have already used memory cache for applications where almost all endpoints were stored in memory, but it was a scenario where there was a daily data update during the night. The data was indeed immutable for almost 24 hours a day. There were millions of data points to serve charts and KPIs, so don't be afraid to use memory cache as long as it makes sense for your project.
CACHE POLICIES
As mentioned earlier, it is easy to implement memory cache in .NET, but it is even easier to make mistakes. When scaling an application that uses cache, there is no guarantee that the data stored in memory during a request will be the same for subsequent requests, because it’s possible that the previous request was handled by server “A” and the subsequent requests by server “B”. In such cases, it is important to consider distributed cache. Options like “Redis” can help solve this problem.
Additionally, when working with memory cache, it is important to define strategies to address potential issues. Imagine a situation where a request returns a list of measurement units: you store the list in memory and quickly return it with a 12-hour expiration time. This scenario seems ideal because, according to the information provided by the client, the data is not frequently updated. However, before the 12-hour expiration period, someone adds a new measurement unit through the back-office, but there are still 8 hours left before the cache expires. It is not comfortable for a client to wait so long to see an updated and available list of measurement units, especially if they need this information to go ahead with other important processes.
In such cases, we need to think of solutions to address these challenges and use common sense to balance performance while providing the client with valuable information. One possible solution is to implement cache policies where we handle important scenarios and adjust our implementation accordingly. For example, the endpoint responsible for creating a new measurement unit can check the existence of the list in memory and clear it using its unique key. This way, the next request for listing measurement units will return eleven units instead of the previous ten, without having to wait for the previously configured expiration time.
The main cache policies are:
-
Absolute expiration: The data is deleted only after its expiration time;
-
Sliding expiration: The item is removed from memory if it has not been accessed for a specified period of time;
-
Size limit: The cache size is limited to the configured value.
Enough chit-chat! Let's get to work!
Let's create an example of an API with various operations, where the goal is to explore customer listing, creation, and removal. Let’s also simulate potential problems and solutions using memory cache.
1. Let's create an API project:
2. Select the project type ASP.NET Core Web API:
3. Name your solution.
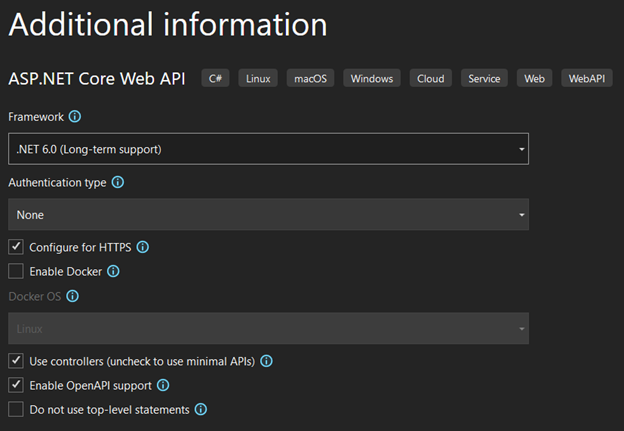
4. Select the .NET 6.0 LTS version and keep the other options as shown in the image. Then click on “Create”.
5. This is the basic structure of your API.
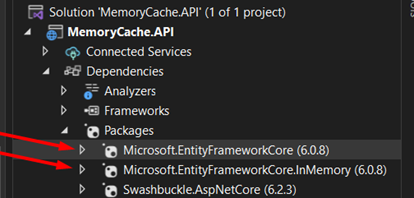
5A. We need to install some packages. To do this, run the following commands in your package manager console:
- Install-Package Microsoft.EntityFrameworkCore
- Install-Package Microsoft.EntityFrameworkCore.InMemory
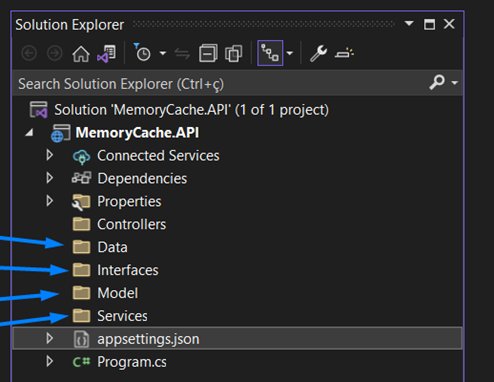
6. I will delete the “WeatherForecastController.cs” and “WeatherForecast.cs” files and create the following folders.
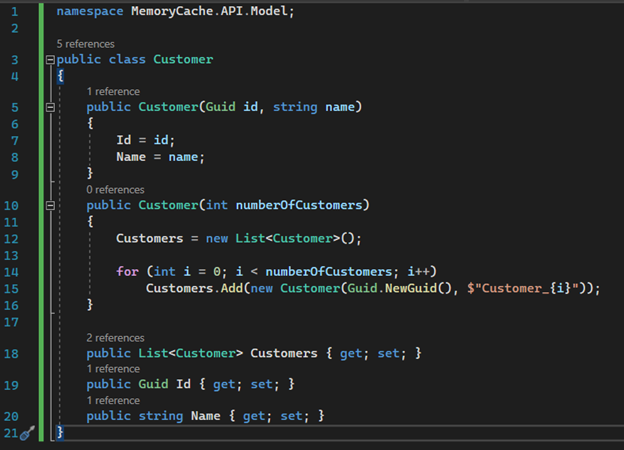
7. Inside the “Models” folder, let's create a class called “Customer”. This class will be used to create a list of customers. It has only an “Id” and “Name”, considering that this is just an example to talk about cache. The class takes the desired number of records as a parameter. To simulate data, I am generating a random “Id” using a Guid and concatenating a name with the loop index.
8. For this project, we will use an in-memory database (note: it is not related to memory cache) so that we don't need to create a real database, which would increase complexity and is not the purpose of this article. Please don't focus on patterns and naming conventions. This example is for educational purposes, so route names, class names, and methods are just examples to illustrate the main idea, which is the use of cache in an API.
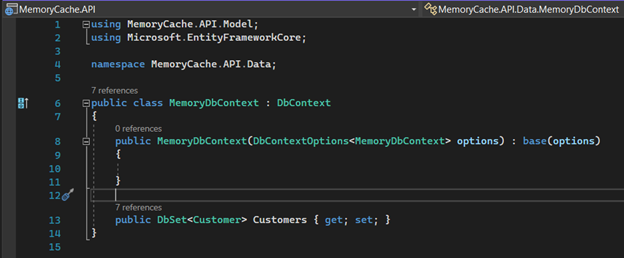
Let's create a file called “MemoryDbContext.cs” inside the “Data” folder. This class should look like this:
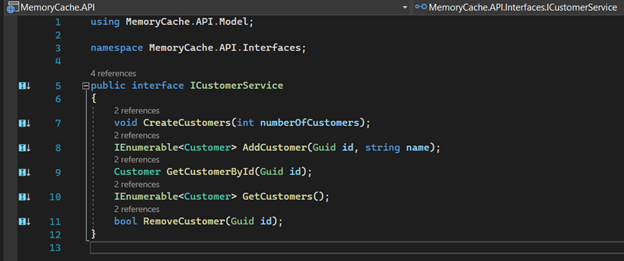
9. In the “Interfaces” folder, let's create our contract with the name “ICustomerService.cs”. It will be responsible for the persistence services.
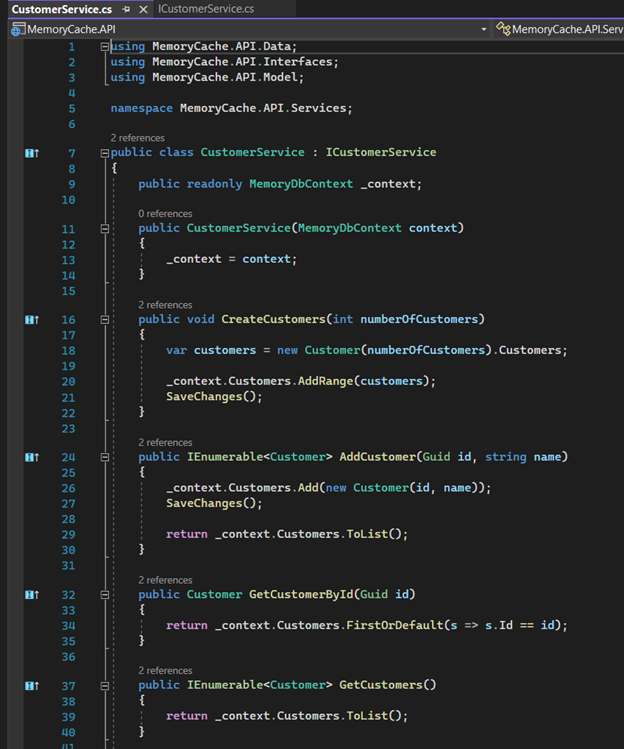
10. In the “Services” folder, we need to create the specific class that implements our interface. Let's call it “CustomerService.cs”.
Part One
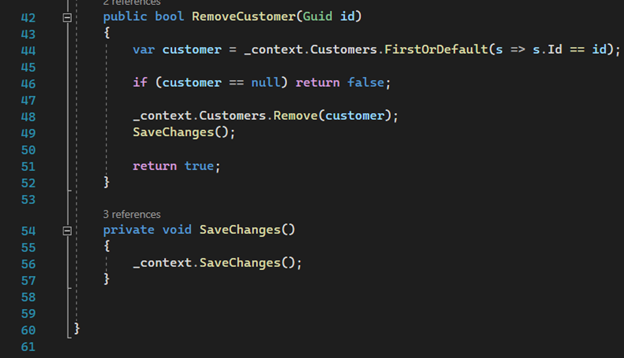
Part Two
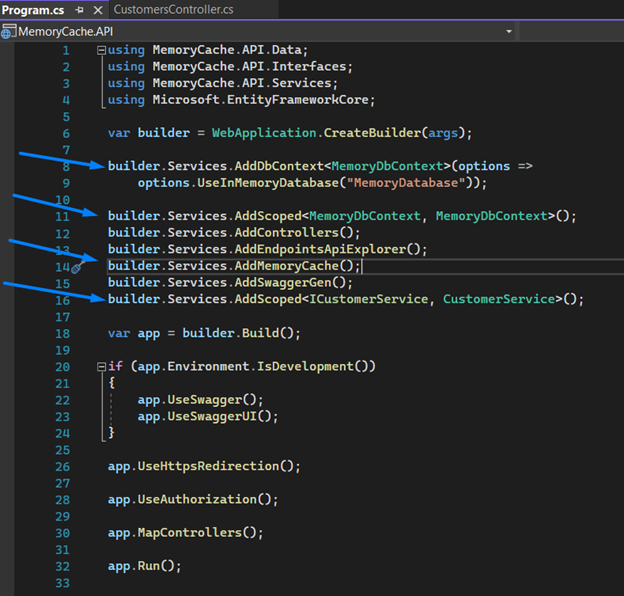
11. Now let's register our dependency injection and our context in the “Program.cs” class.
Note: We will also register the “AddMemoryCache()” extension method on line 14, which will allow us to implement the cache usage interface.
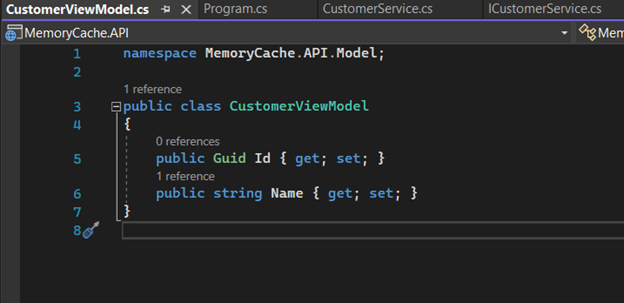
12. We're almost there. Inside the “Models” folder, let's create a class that will serve as the data transport when creating a Customer. Let's call it “CustomerViewModel.cs”.
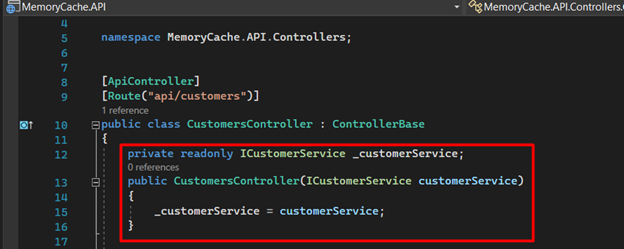
13. Finally, let's create our controller, which will receive the requests. Initially, we will implement it without using cache. Firstly, we inject our service into the controller's constructor.
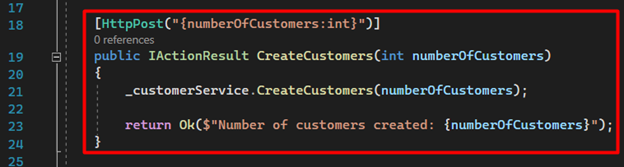
14. Next, we create our first route, which is responsible for creating a list of customers. You only need to provide the desired quantity – this will add the customers to our database, which we will use for other operations.
15. We create two more endpoints. The first one allows us to retrieve a customer by Id, and the second one allows us to retrieve the complete list of customers in the database.
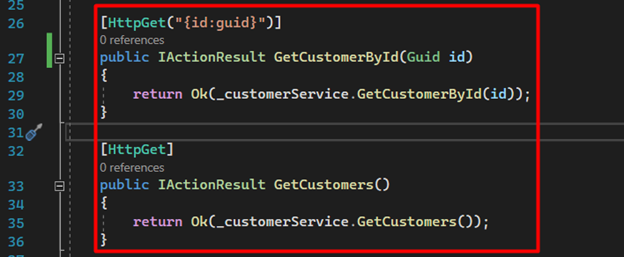
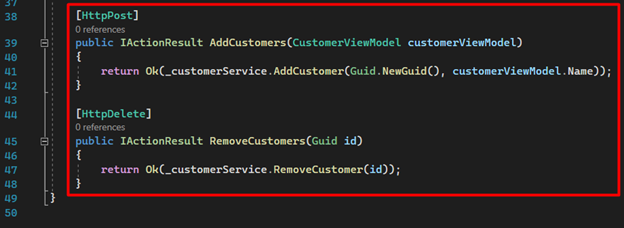
16. The last two endpoints are responsible for creating and removing customers.
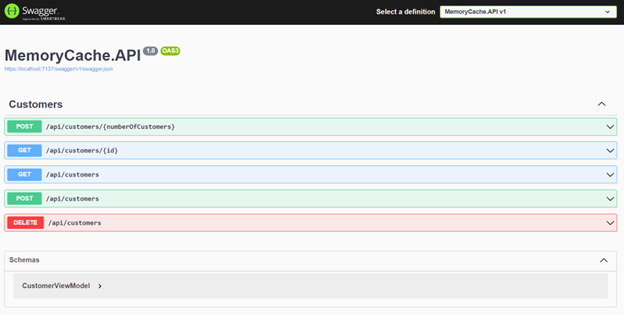
17. Now we can run our application. If everything goes as planned, you should see the following page.
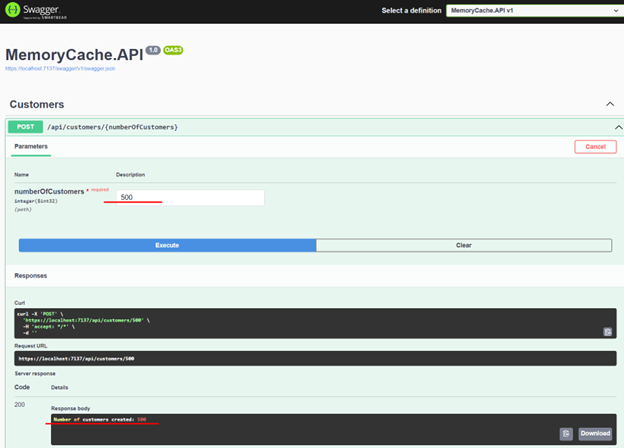
18. Let's now consume each endpoint to see the initial results. We'll start by creating 500 new customers.
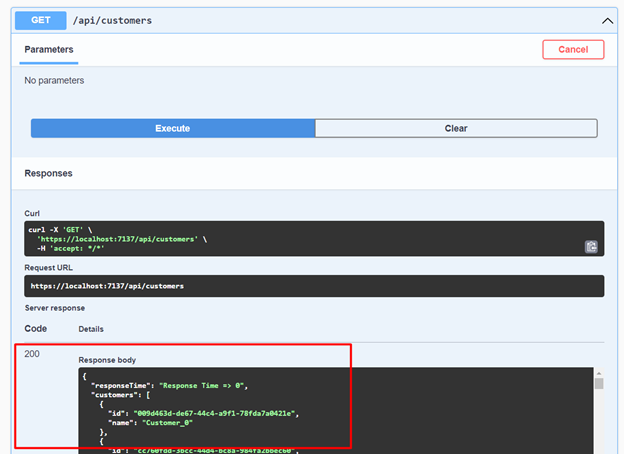
19. When listing the customers, we'll observe the following result.
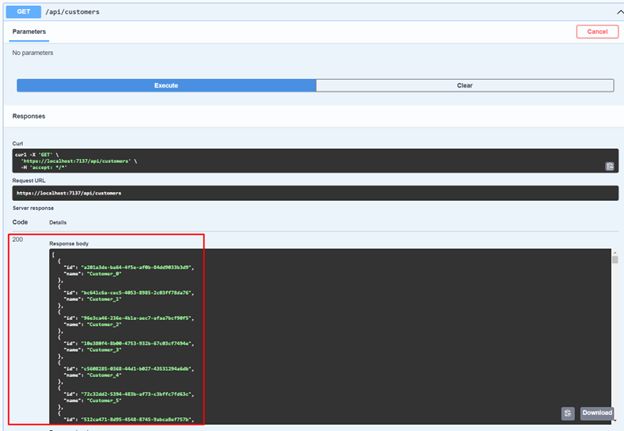
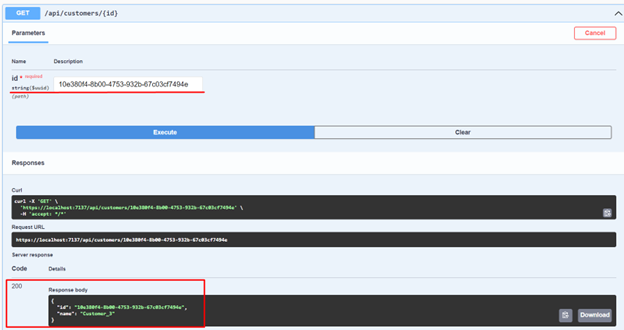
20. Now let's copy one of these Ids to retrieve a single customer. In my case, I used the Id of Customer_3.
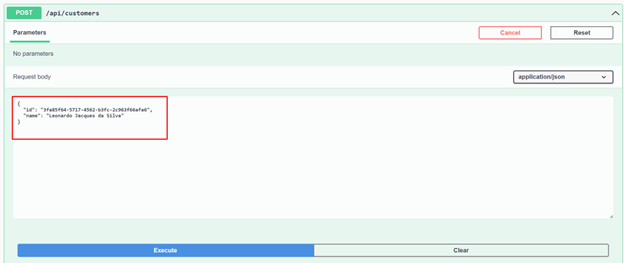
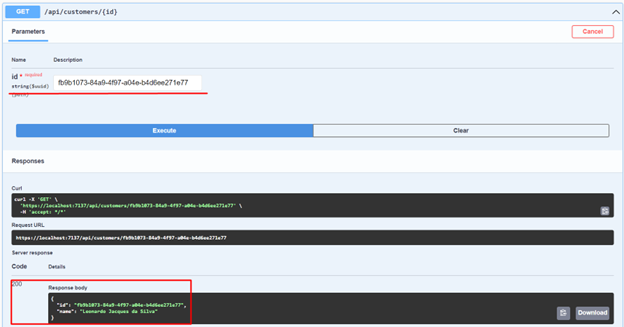
21. Next, let's create a customer and retrieve it again by Id to make sure it was created.
22. Finally, let's remove a customer by their Id.
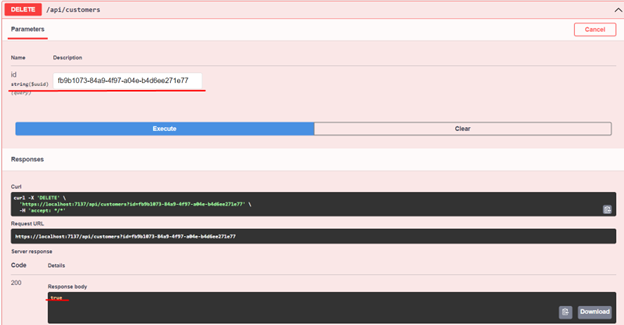
Well, we've come this far by creating a fully functional API with almost all of the operations. Now let's implement the use of cache and observe a significant increase in performance. We will also remove the data from memory as soon as a customer is created or removed, even before its expiration time.
1. We inject the IMemoryCache interface into the constructor of the “CustomerService.cs” service.
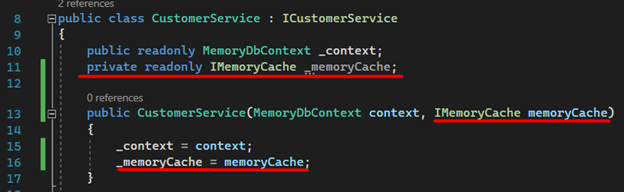
2. The method that returns all customers should be modified to validate if the list is already in memory. If there is an existing list in memory, it will be immediately returned to the controller without querying the database. This will continue until the expiration time or until there is a deletion/insertion operation.
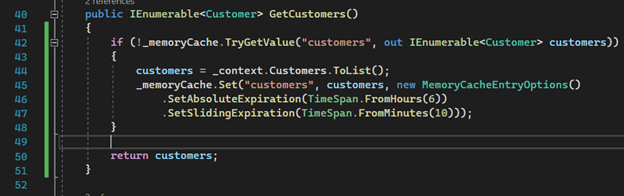
Important note: The “MemoryCacheEntryOptions” allows us to configure important options. In our case, on line 46, I set the absolute expiration time to 6 hours. However, if the service is not accessed for 10 minutes, it will be removed from memory. There are other options like “SetPriority”, “SetSize”, etc. You can find more information in the Microsoft documentation (I will share the link at the end of the article).
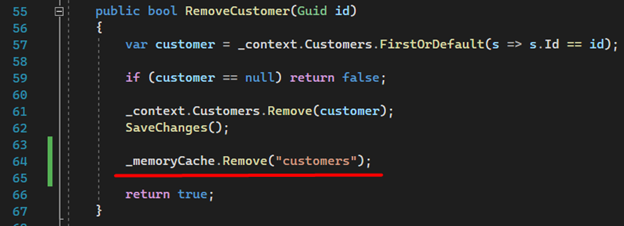
3. Now comes a very important part of our implementation. The removal or addition of a new customer should delete the data from memory, ensuring that the next request will have the updated list.
In the AddCustomer method:
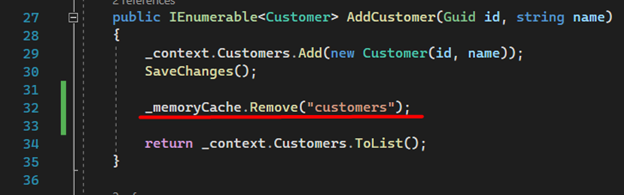
In the RemoveCustomers method:
API PERFORMANCE
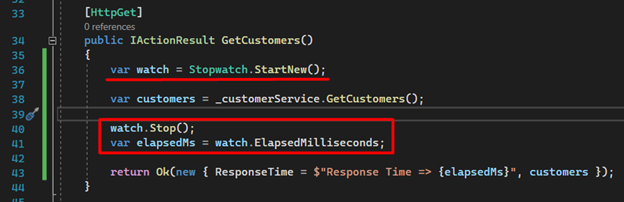
With our implementation almost complete, we can discuss the API’s improved performance. Let's modify our controller to return not only the data, but also the response time using cache.
Please note that the first call to the “GetCustomers()” endpoint will take longer because it is retrieving the data from our database and storing it in memory.
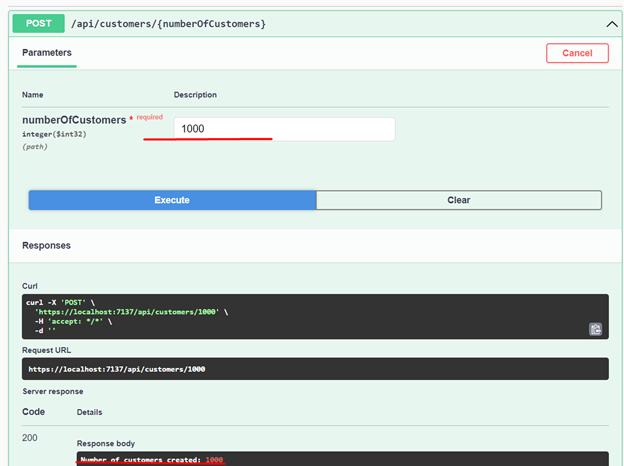
Let's initially create 1000 records.
Now let's retrieve all the customers. Notice that the response for the 1000 records took 157 milliseconds.
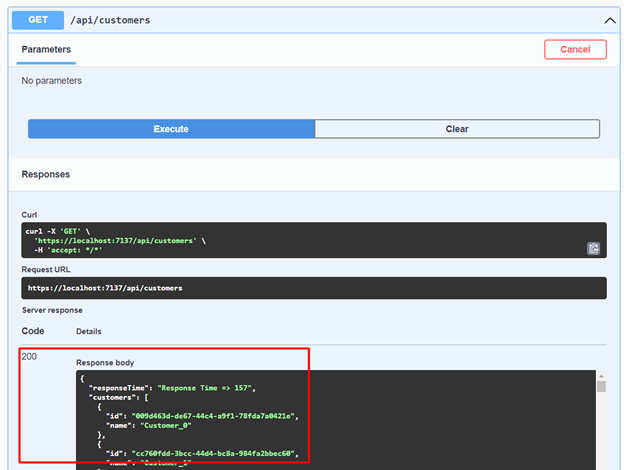
Let's consume the same service again. Surprisingly, we can see that the response took less than 1 millisecond – a significant performance gain. Just imagine the efficiency this can bring to your projects when implementing cache.
CONCLUSION
Memory Cache is a great alternative for those seeking performance improvement, enhancing the customer experience, reducing database load, and saving cloud resources.
It's important to note that it's not a solution for every scenario, and careful consideration is required when implementing it. When thoughtfully implemented, it can greatly improve your application.
MORE INFORMATION:
- Github: Github Leosul Memory Cache Sample
- LinkedIn: LinkedIn Memory Cache Article
- Medium: Medium Memory Cache Article
REFERENCES:
